Introduction
Modern organizations depend on analytics to guide decisions, optimize operations, and uncover growth opportunities. Yet despite massive investments in data platforms, many analytics initiatives fail quietly. Dashboards show the wrong numbers, reports arrive late, and stakeholders lose confidence. These failures are rarely caused by lack of data. Instead, they stem from invisible breakdowns across complex pipelines. This is where Data Observability Practices become essential. Rather than reacting to broken dashboards after the damage is done, observability helps teams detect issues early, understand root causes, and maintain trust in analytics outputs. As data ecosystems grow more distributed and automated, observability is no longer optional. It is a foundational capability for teams that want consistent, reliable insights and long-term analytics success.
Why Analytics Fail in Growing Data Environments
Analytics failures often begin long before anyone notices a broken report. Data flows through ingestion tools, transformation layers, warehouses, and visualization platforms. Each handoff introduces risk. Without systematic oversight, small issues compound into major failures.
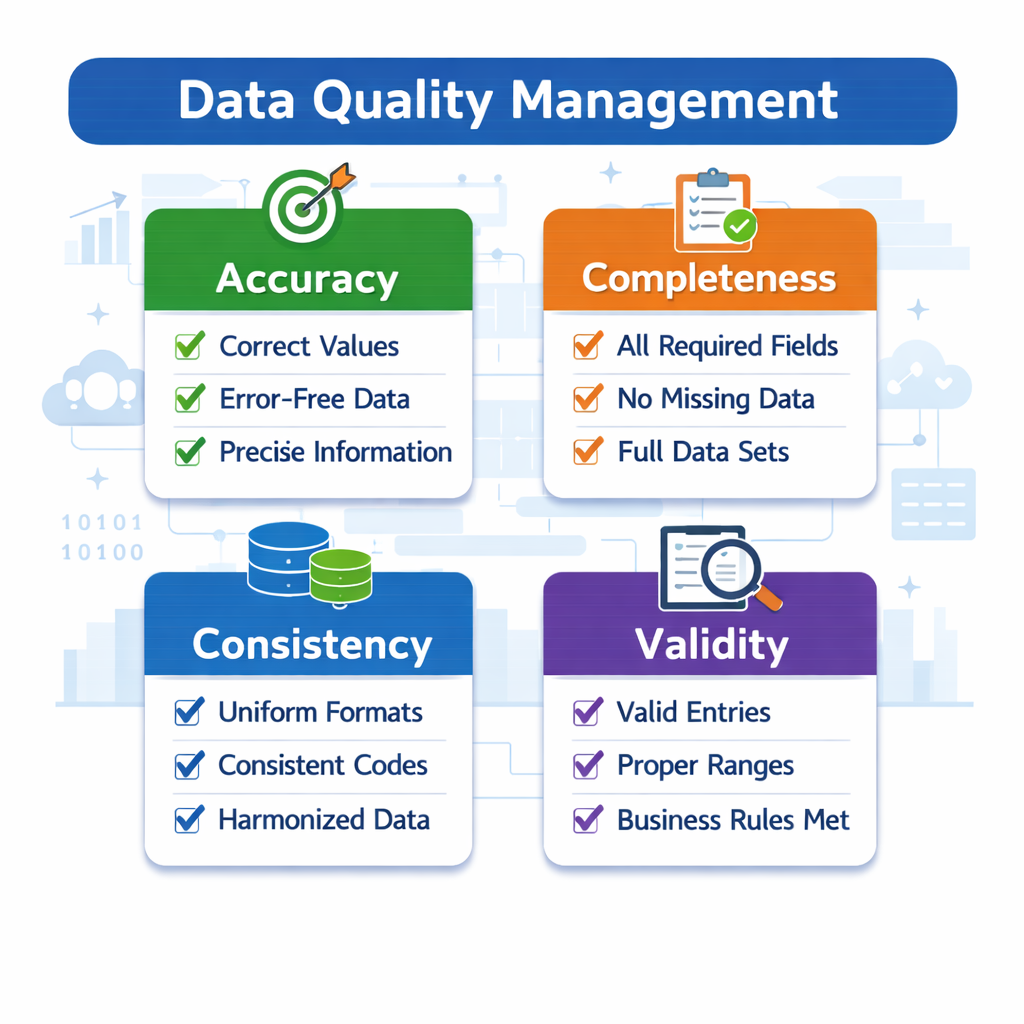
Common causes include schema changes that go unnoticed, upstream data delays, silent data quality degradation, and transformation logic that no longer matches business rules. Manual checks cannot scale with modern data volumes. This is why Analytics failure prevention requires continuous visibility, not periodic audits.
Another challenge is organizational. Data teams are under pressure to deliver fast, leaving little time for proactive monitoring. When failures occur, engineers scramble to fix symptoms instead of addressing root causes. Over time, analytics reliability erodes, and stakeholders revert to gut-based decision-making. Effective Data Observability Practices shift teams from firefighting to prevention by embedding monitoring, alerting, and accountability directly into data workflows.
What Data Observability Really Means
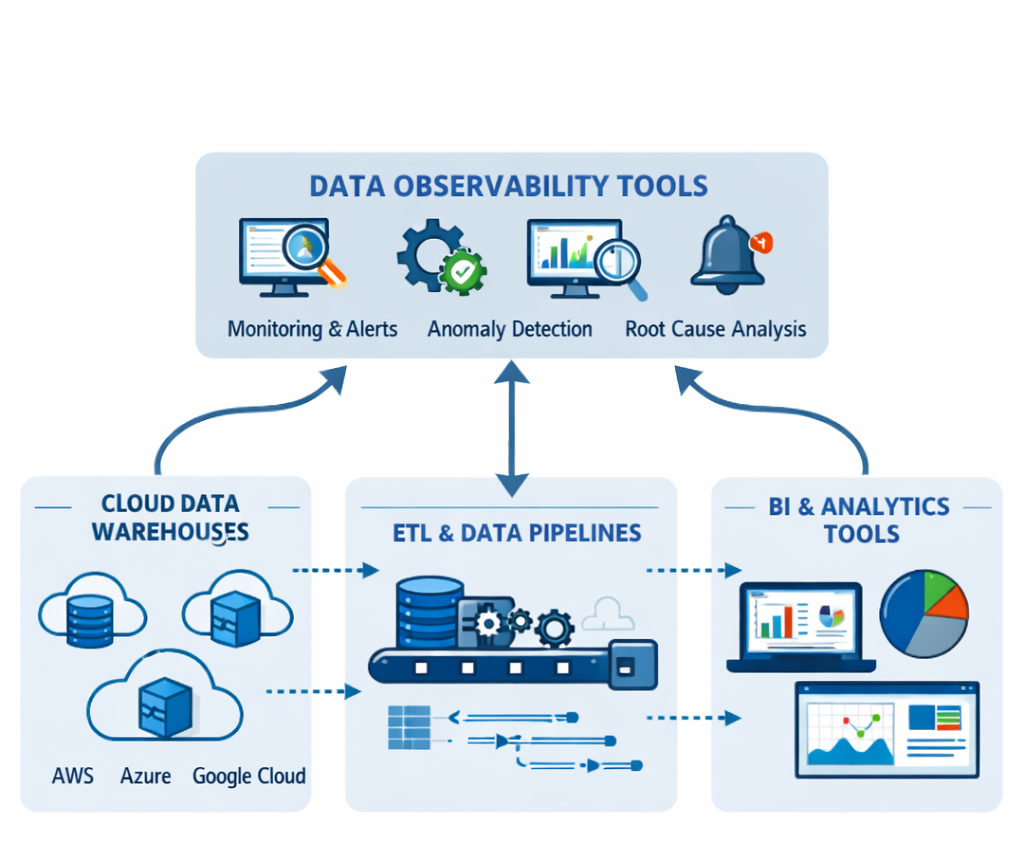
Data observability applies proven monitoring concepts from software engineering to analytics systems. It focuses on understanding the health of data by tracking signals across the entire lifecycle. At its core, observability answers four questions: Is the data fresh? Is it complete? Is it accurate? Can issues be traced to their source?
Unlike traditional data quality checks, observability is continuous and automated. It does not rely on static rules alone. Instead, it detects anomalies, trends, and unexpected behavior. This makes Data Observability Practices especially valuable in dynamic environments where schemas, sources, and business logic evolve frequently.
Strong observability also supports accountability. When issues arise, teams can trace lineage, identify responsible systems, and resolve problems faster. This clarity is essential for maintaining analytics reliability at scale and for supporting advanced use cases like machine learning and real-time reporting.
Core Data Observability Practices That Prevent Failures
Effective observability is not a single tool or dashboard. It is a discipline built on several complementary practices that work together.
Data Pipeline Monitoring Across the Stack
Modern analytics depends on complex pipelines. Data pipeline monitoring ensures each stage performs as expected, from ingestion to transformation to consumption. Monitoring should cover execution times, failure rates, and unexpected volume changes.
Key monitoring signals include:
-
Delays compared to historical baselines
-
Missing or duplicated records
-
Sudden drops or spikes in row counts
-
Failed or skipped transformations
By tracking these indicators continuously, teams can identify issues before downstream dashboards break. This proactive visibility is central to Data Observability Practices that scale.