Artificial intelligence is no longer a future ambition—it is a present-day competitive necessity that is reshaping how organizations operate, compete, and innovate. Businesses across industries are investing heavily in machine learning, predictive analytics, and automation to unlock deeper insights and improve efficiency. However, many organizations overlook a critical truth: successful AI adoption does not begin with algorithms or models—it begins with a strong and reliable AI-Ready Data Infrastructure that can support those initiatives at scale.
An AI-Ready Data Infrastructure ensures that data is not only available but also structured, clean, and accessible in real time for analysis and model training. It allows organizations to move seamlessly from raw data to meaningful insights without unnecessary delays or inconsistencies. Before you start building AI models or deploying machine learning systems, it is essential to evaluate whether your existing data stack is capable of handling the complexity, speed, and scale required for AI-driven operations.
At its core, AI-Ready Data Infrastructure refers to a comprehensive system designed to collect, store, process, and deliver data in a way that supports artificial intelligence and machine learning workflows. It goes beyond traditional data systems by enabling continuous data flow, scalability, and seamless integration across multiple platforms and tools. This infrastructure acts as the foundation upon which AI models are built and deployed.
Unlike conventional analytics environments that focus mainly on reporting and dashboards, AI-Ready Data Infrastructure must support experimentation, iterative model training, and real-time decision-making. It is designed to handle both structured data, such as databases, and unstructured data, such as images, text, and logs. This flexibility is crucial for organizations aiming to leverage AI across diverse use cases and data sources.
Many organizations still rely on legacy data systems that were originally designed for static reporting rather than dynamic intelligence. These systems often struggle to keep up with the demands of modern AI applications, leading to inefficiencies and unreliable outcomes. As data volumes grow and business needs evolve, the limitations of outdated infrastructure become increasingly evident.
Common challenges with traditional stacks include data silos that prevent seamless integration, limited scalability that restricts growth, and slow processing speeds that delay insights. Additionally, inconsistent data quality and lack of real-time capabilities make it difficult to build accurate AI models. Without addressing these issues, transitioning to an effective AI-Ready Data Infrastructure becomes significantly more complex and resource-intensive.
A scalable data architecture forms the backbone of any successful AI initiative, ensuring that systems can handle increasing data volumes without compromising performance. As organizations grow, their data requirements expand, making scalability a critical factor in long-term success. A well-designed architecture allows businesses to adapt quickly to changing demands without requiring frequent overhauls.
Key features of a scalable architecture include distributed storage systems that manage large datasets efficiently, cloud-native platforms that offer flexibility, and elastic compute resources that adjust based on workload requirements. These capabilities ensure that your AI-Ready Data Infrastructure remains robust and efficient, even as data complexity increases over time.
For a deeper understanding, you can explore this detailed guide on data architecture by IBM.
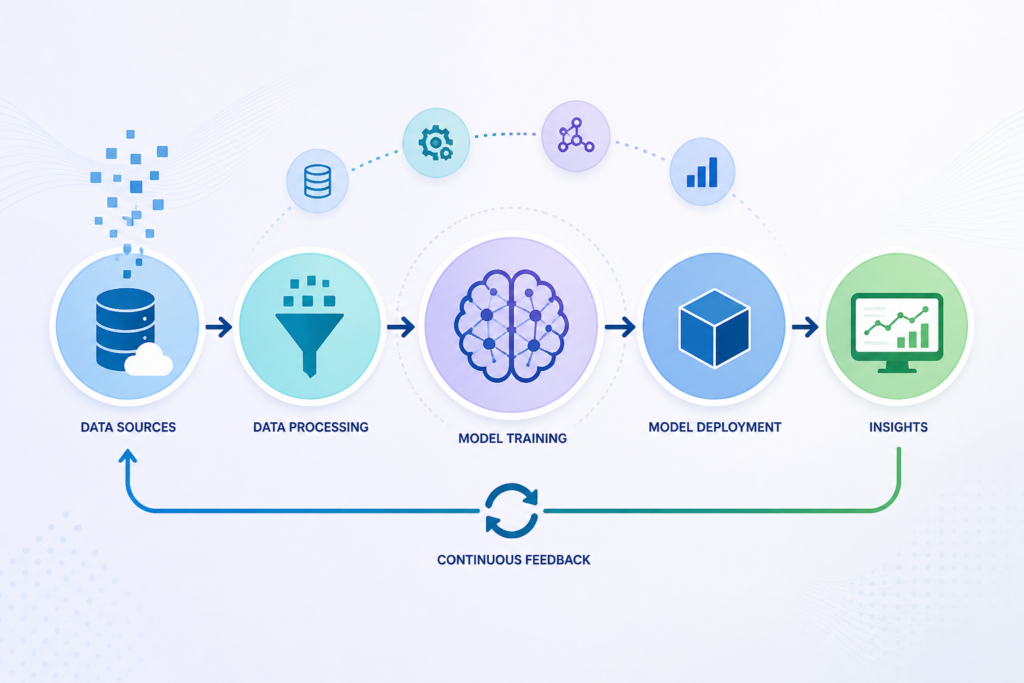
A well-structured data pipeline for machine learning is essential for ensuring that data flows smoothly from source systems to AI models. This pipeline automates the processes of data ingestion, transformation, and delivery, reducing manual effort and minimizing errors. It plays a crucial role in maintaining consistency and reliability across datasets.
An effective pipeline should be capable of ingesting data from multiple sources, cleaning and normalizing it, and preparing it for analysis through feature engineering. It should also support versioning and monitoring to track changes and ensure reproducibility. Without a robust pipeline, maintaining data integrity becomes challenging, directly impacting the performance of AI models.
The modern data stack represents a combination of tools and technologies designed to streamline data operations and improve efficiency. It integrates specialized solutions for data ingestion, storage, transformation, and visualization, enabling teams to build and manage AI-Ready Data Infrastructure more effectively. This modular approach allows organizations to choose best-in-class tools tailored to their specific needs.
Typically, a modern data stack includes data ingestion tools like Fivetran or Airbyte, cloud data warehouses such as Snowflake or BigQuery, transformation tools like dbt, and visualization platforms like Tableau or Looker. Together, these components create a cohesive ecosystem that supports scalable and efficient data workflows. To explore how these tools can be implemented, visit the Engine Analytics services page.
Effective AI data management ensures that data remains accurate, consistent, and secure throughout its lifecycle. It involves implementing governance frameworks, maintaining data quality, and ensuring compliance with regulatory requirements. Strong data management practices are essential for building trust in AI systems and their outputs.
Key elements of AI data management include data cataloging, which helps organize and locate datasets; metadata management, which provides context and meaning; and data quality monitoring, which ensures accuracy and reliability. By prioritizing these aspects, organizations can reduce risks and improve the overall effectiveness of their AI-Ready Data Infrastructure.
A dedicated data infrastructure for AI is required to support the computational demands of machine learning and deep learning models. These workloads often involve processing large datasets and performing complex calculations, which require high-performance computing environments. Without the right infrastructure, training and deploying models can become time-consuming and inefficient.
This includes GPU-enabled environments for accelerated processing, distributed computing frameworks for handling large-scale tasks, and high-throughput storage systems for quick data access. These capabilities ensure that your AI-Ready Data Infrastructure can support advanced AI applications and deliver results efficiently.
The first step in building AI-Ready Data Infrastructure is to conduct a thorough assessment of your existing data systems. This involves identifying where your data is stored, how it is processed, and whether there are any inefficiencies or redundancies. Understanding your current landscape provides a clear starting point for improvement.
By analyzing your data flows and identifying bottlenecks, you can determine which areas require immediate attention. This assessment also helps in prioritizing investments and aligning your infrastructure with business objectives.

Defining clear objectives is essential for ensuring that your AI-Ready Data Infrastructure aligns with your organization’s strategic goals. Whether your focus is on improving customer experience, optimizing operations, or driving revenue growth, having a clear vision guides your infrastructure decisions.
These objectives should be measurable and actionable, allowing teams to track progress and evaluate success. Clear goals also help in selecting the right tools and technologies for your data stack.
Data fragmentation is one of the biggest barriers to effective AI implementation. Centralizing and integrating data from various sources ensures that your AI-Ready Data Infrastructure provides a unified view of information. This integration enables better analysis and more accurate insights.
By consolidating data into a single platform, organizations can eliminate silos and improve collaboration across teams. This unified approach also simplifies data management and enhances overall efficiency.
Adopting scalable solutions is crucial for building a future-proof AI-Ready Data Infrastructure. As data volumes grow and business needs evolve, your infrastructure must be able to adapt without requiring significant changes. Scalability ensures long-term sustainability and cost efficiency.
Cloud-based platforms and distributed systems provide the flexibility needed to handle increasing workloads. These solutions allow organizations to scale resources up or down based on demand, ensuring optimal performance at all times.
Investing in a reliable data pipeline for machine learning is essential for maintaining consistency and efficiency in data workflows. A well-designed pipeline automates repetitive tasks and ensures that data is always up to date and ready for analysis.
This not only reduces manual effort but also minimizes errors, improving the overall quality of your data. A robust pipeline is a key component of any successful AI-Ready Data Infrastructure.
High-quality data is the foundation of effective AI systems. Without it, even the most advanced models will produce inaccurate results. Ensuring data quality involves implementing validation checks, monitoring systems, and cleaning processes to maintain consistency.
By prioritizing data quality, organizations can improve model performance and build trust in their AI solutions. This is a critical aspect of maintaining a reliable AI-Ready Data Infrastructure.
Modern AI applications often require real-time insights to support decision-making. Enabling real-time capabilities within your AI-Ready Data Infrastructure allows organizations to respond quickly to changing conditions and opportunities.
This involves implementing streaming data solutions and event-driven architectures that process data as it is generated. Real-time capabilities enhance agility and provide a competitive advantage in fast-paced environments.
Building AI-Ready Data Infrastructure comes with its own set of challenges, including data silos, scalability issues, and security concerns. Addressing these challenges requires a strategic approach and the right combination of tools and expertise.
Organizations can overcome these obstacles by adopting cloud-native solutions, implementing strong security measures, and fostering collaboration across teams. For tailored guidance, you can contact Engine Analytics to explore solutions that fit your specific needs.
To ensure the long-term success of your AI-Ready Data Infrastructure, it is important to follow best practices that promote efficiency and adaptability. These practices help organizations stay ahead of technological advancements and maintain a competitive edge.
Key best practices include prioritizing data governance, automating workflows, continuously monitoring performance, and investing in team collaboration. By following these principles, businesses can build a resilient and future-ready data infrastructure.
Building AI-Ready Data Infrastructure is the most critical step in unlocking the full potential of artificial intelligence. It provides the foundation for scalable, efficient, and reliable AI systems that drive business value. By focusing on scalability, integration, and data quality, organizations can create a robust infrastructure that supports innovation and growth.
If you are ready to transform your data strategy and build a future-proof system, visit Engine Analytics to get started and take the first step toward becoming an AI-driven organization.
An AI-Ready Data Infrastructure goes beyond basic storage and reporting capabilities—it is specifically designed to support the full lifecycle of artificial intelligence and machine learning. This means it must handle large-scale data ingestion, enable fast and flexible processing, and ensure that data is always clean, consistent, and accessible.
In practice, this includes having a scalable data architecture that can grow with increasing data volumes, robust AI data management practices to maintain quality and governance, and integrated systems that support both batch and real-time processing. It also needs to enable seamless collaboration between data engineers, analysts, and data scientists. When all these elements come together, organizations can build, train, test, and deploy AI models efficiently without bottlenecks or reliability issues.
A data pipeline for machine learning is critical because it ensures that data flows smoothly and consistently from source systems to AI models without manual intervention. AI models depend heavily on the quality and consistency of input data, and even small inconsistencies can significantly impact performance.
A well-designed pipeline automates key processes such as data ingestion, cleaning, transformation, and feature engineering. It also supports monitoring and version control, allowing teams to track changes and reproduce results when needed. This not only improves model accuracy but also accelerates development cycles. Without a strong pipeline, teams often spend more time fixing data issues than building models, which slows down innovation and reduces efficiency.
The modern data stack plays a crucial role in enabling AI by providing a flexible, modular, and scalable ecosystem for managing data workflows. Instead of relying on a single monolithic system, it combines specialized tools for different stages of the data lifecycle, including ingestion, storage, transformation, and visualization.
This approach allows organizations to choose best-in-class tools that integrate seamlessly, improving performance and adaptability. For example, cloud data warehouses handle large-scale storage, transformation tools prepare data for analysis, and analytics platforms provide insights for decision-making. Together, these components create a streamlined environment that supports experimentation, rapid iteration, and scaling of AI applications. As a result, businesses can move faster from raw data to actionable intelligence while maintaining efficiency and control.
